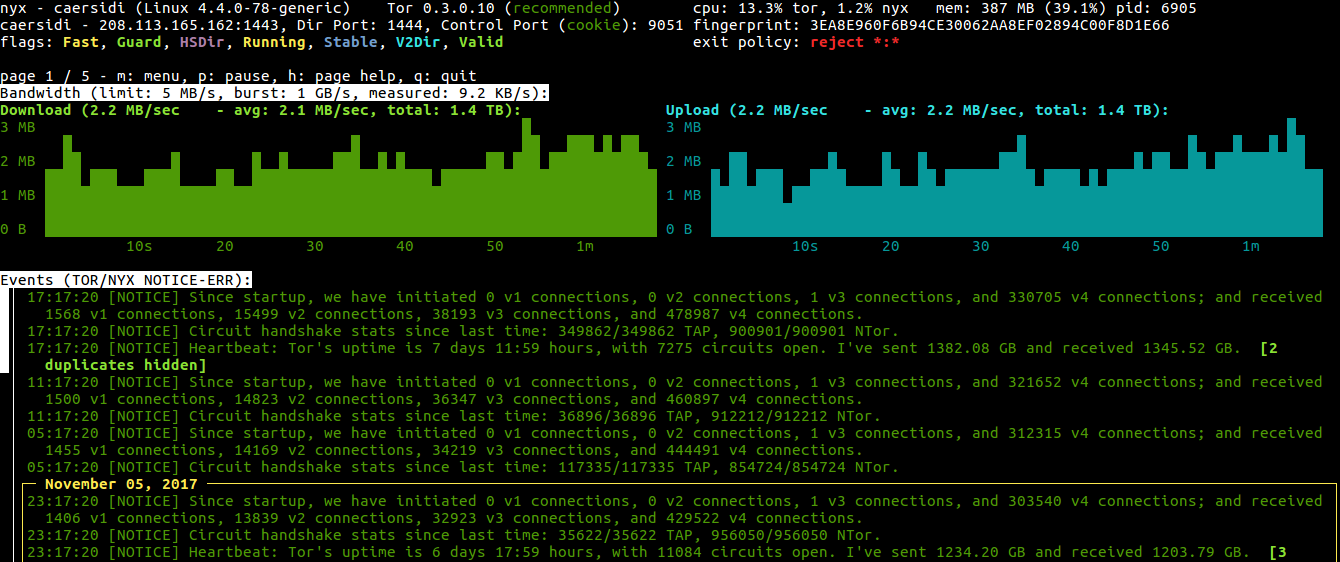
Hi all. This month been down in the engine room productionizing Nyx, with a special focus on memory usage. Dropped ~13%, but still not where I want so investigations are ongoing.
Nyx SQLite Cache
Main benefit came from moving cached consensus information from memory to SQLite. Besides the obvious memory benefits this allows the cache to persist between invocations, halving Nyx’s startup time (from 0.7 to 0.3 seconds).
Tor Manual Database
Stem provides easy programmatic access for Tor’s manual information. SQLite now backs this information, providing 8x faster reads (Manual.from_cache() dropped 16ms to 2ms), and now supports random access reads…
>>> import stem.manual
>>> print(stem.manual.query('SELECT description FROM torrc WHERE key=?', 'CONTROLSOCKET').fetchone()[0])
Like ControlPort, but listens on a Unix domain socket, rather than a TCP socket. 0 disables ControlSocket (Unix and Unix-like systems only.)
This further drops Nyx’s memory usage by allowing it to only fetch the manual information it needs.
Stem Multi-Processing
May’s test performance investigation has now led to a general purpose DaemonTask class to make Python multi-processing easy…
Threaded
import threading
import time
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n-2) + fibonacci(n-1)
# calculate fibonacci sequences four times in parallel
start_time, threads = time.time(), []
for i in range(4):
t = threading.Thread(target = fibonacci, args = (35,))
t.setDaemon(True)
t.start()
threads.append(t)
for t in threads:
t.join()
print('took %0.1f seconds' % (time.time() - start_time))
% python fibonacci_threaded.py
took 21.1 seconds
Multi-Process
import stem.util.system
import time
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n-2) + fibonacci(n-1)
# calculate fibonacci sequences four times in parallel
start_time, threads = time.time(), []
for i in range(4):
threads.append(stem.util.system.DaemonTask(fibonacci, (35,), start = True))
for t in threads:
t.join()
print('took %0.1f seconds' % (time.time() - start_time))
% python fibonacci_multiprocessing.py
took 6.2 seconds
Presently this is only used for our tests, but soon I'll take advantage of this to make Nyx more performant on multi-core systems.